概要
由于ChatGPT生成的执行代码无法保证系统的稳定性和安全性。ChatGPT 可能会为同一任务提供不同的答案,从而导致不可预测性。这种不稳定性阻止了 ChatGPT 直接集成到机器人操作循环中。在这里我们介绍 RobotGPT,一个创新优先考虑稳定性和安全性的机器人操作决策框架。我们的目标是利用 ChatGPT 在机器人操纵方面解决问题的能力,并训练可靠的代理。该框架包括一个有效的提示结构和一个强大的学习模型。
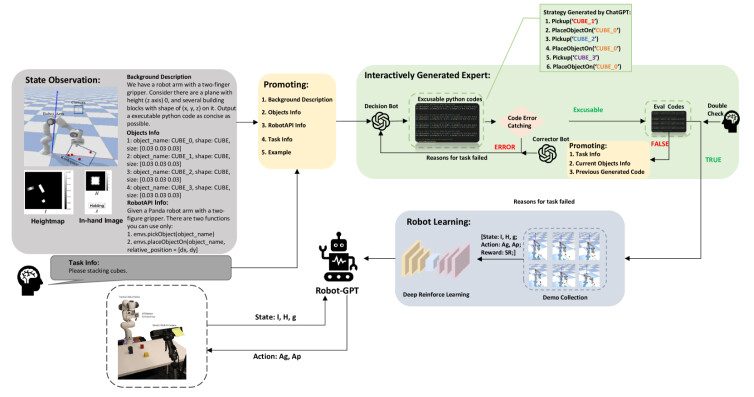
图 1:我们系统的架构。ChatGPT在其中扮演着三个角色,分别是决策机器人、评估机器人和校正机器人。操作者发出指令让机器人完成任务,然后根据环境信息和人类指令生成自然语言提示。 决策机器人将根据提供的提示生成相应的可执行代码。接下来,生成的代码将逐行执行。如果发生运行时错误,将提供此错误的原因和发生错误的代码行,供决策机器人修改,直到代码可以成功运行。然后,可执行代码将由评估机器人生成的评估代码模型进行测试。如果可执行代码无法通过 Eval 代码,则校正器机器人将分析结果失败的潜在原因,并将这些失败原因发送回决策机器人进行更正。 之后,满足评估条件的代码将用于生成演示数据。经过训练后,训练有素的智能体可以完美地部署真正的机器人。
方法论
机器人技术的 LLM
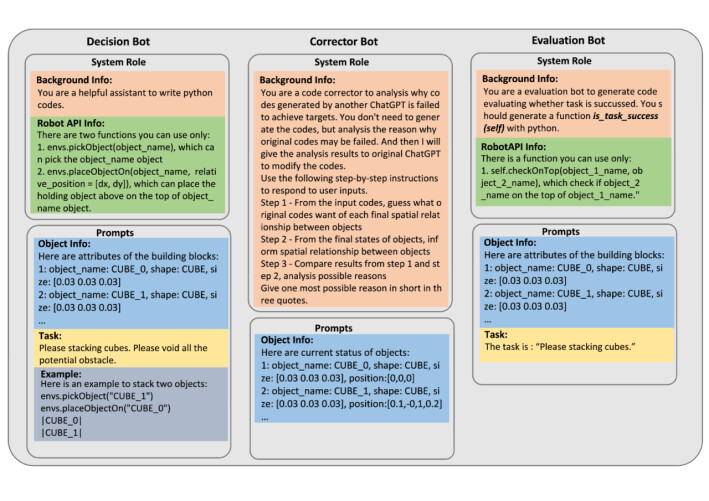
机器人学习
I行动、状态空间和奖励
II算法
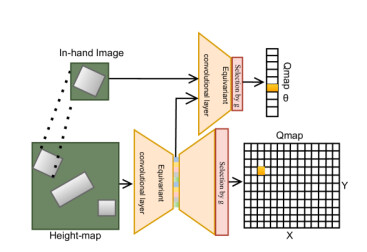
图3:机器人学习网络架构
实验
实验设置
图5显示了我们在模拟和真实环境中的实验设置。我们在工作区正上方安装了RGB-D传感器,以提供清晰的场景高度图。在模拟环境中,机器人依靠 PyBullet 引擎进行运动控制。在现实世界中,机器人利用 MoveIt 和 ros_franka 进行运动规划和执行。
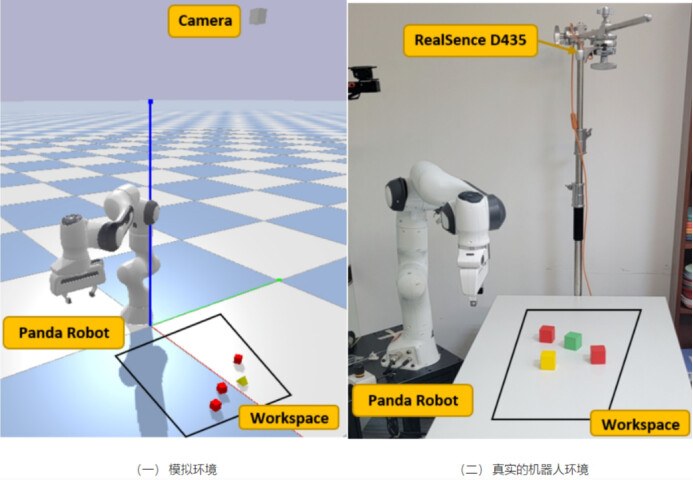
仿真实验
表三列出了八项实验的定量结果。事实是,尽管每次都输入相同的提示,但生成的代码和生成的输出总是有显着差异,因为决策机器人的温度是 1.0。此外,ChatGPT 生成的代码包含语法或逻辑错误。虽然我们的自我修正模块可以修正一些语法错误,但在大多数情况下,如果 ChatGPT 最初无法生成成功的代码,那么在这个实验中就很难取得成功。
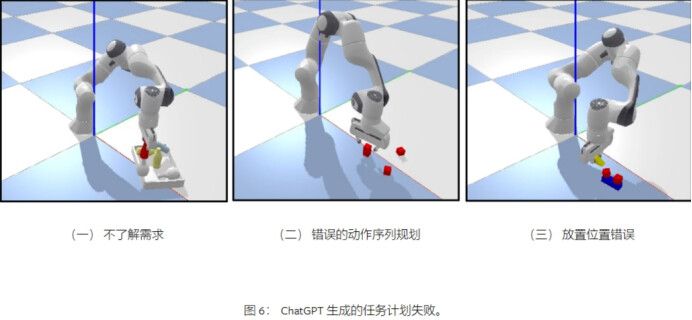
图6说明了ChatGPT生成的错误规划导致的三种最常见的失败。无花果。图6(a)显示了由于对任务要求的误解而导致的失败。bottle_arrangement任务需要将瓶子整齐地放在托盘上,而不是随意将它们放在托盘上。无花果。图6(b)呈现了错误的动作序列规划,其中机器人正在抓取图像中堆叠的块。这显然是不合理的,因为机器人应该抓取尚未堆叠的物体。在图中。如图6(c)所示,机器人的放置位置明显偏差。因此,ChatGPT 可以为相同的提示提供不同的解决方案,其中一些是正确的,而另一些则不正确。这就是为什么我们提出 RobotGPT 框架作为一种更稳定的方法。
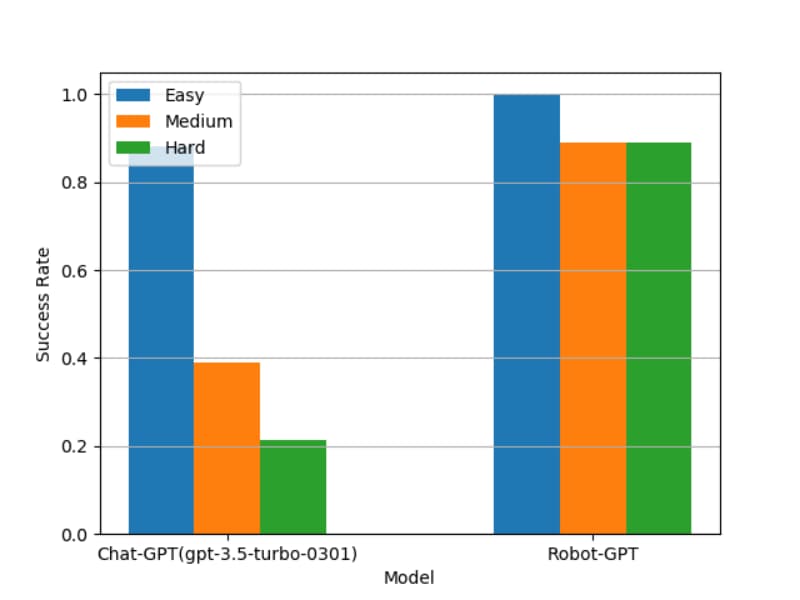
图7:三个难度级别的成功率
图7 显示三个难度级别的成功率。对于ChatGPT来说,很明显,随着任务难度的增加,成功率会显着降低。简单、中等和困难任务的成功率分别为 0.88、0.39 和 0.21。相比之下,我们的 RobotGPT 模型在所有级别的任务中都表现出鲁棒性,保持了良好的性能,平均可以达到 0.915。
真正的机器人实验

真实机器人实验的计数结果
| 任务名称 | 成功 | 失败 | 总 | AP |
|---|---|---|---|---|
| 移动立方体(E) | 8 | 2 | 10 | 0.8 |
| 砌块堆叠(M) | 6 | 4 | 10 | 0.6 |
| 金字塔堆叠(M) | 7 | 3 | 10 | 0.7 |
| 房屋建筑 1(M) | 9 | 1 | 10 | 0.9 |
| 房屋建筑 2(M) | 6 | 4 | 10 | 0.6 |
| 料仓包装(H) | 7 | 3 | 10 | 0.7 |
AB测试
为了研究我们的LLM驱动的机器人解决非LLM方法无法很好地解决的问题的能力,我们引入了两个开放式实验,如图所示。图 9 所示。第一个实验涉及整理房间的挑战,需要整理 40 件定制的家居用品,而第二个实验是一个拼写单词游戏,旨在使用给定的字母集 A-L 拼写最长的单词。此外,我们邀请人类受试者完成相同的任务。
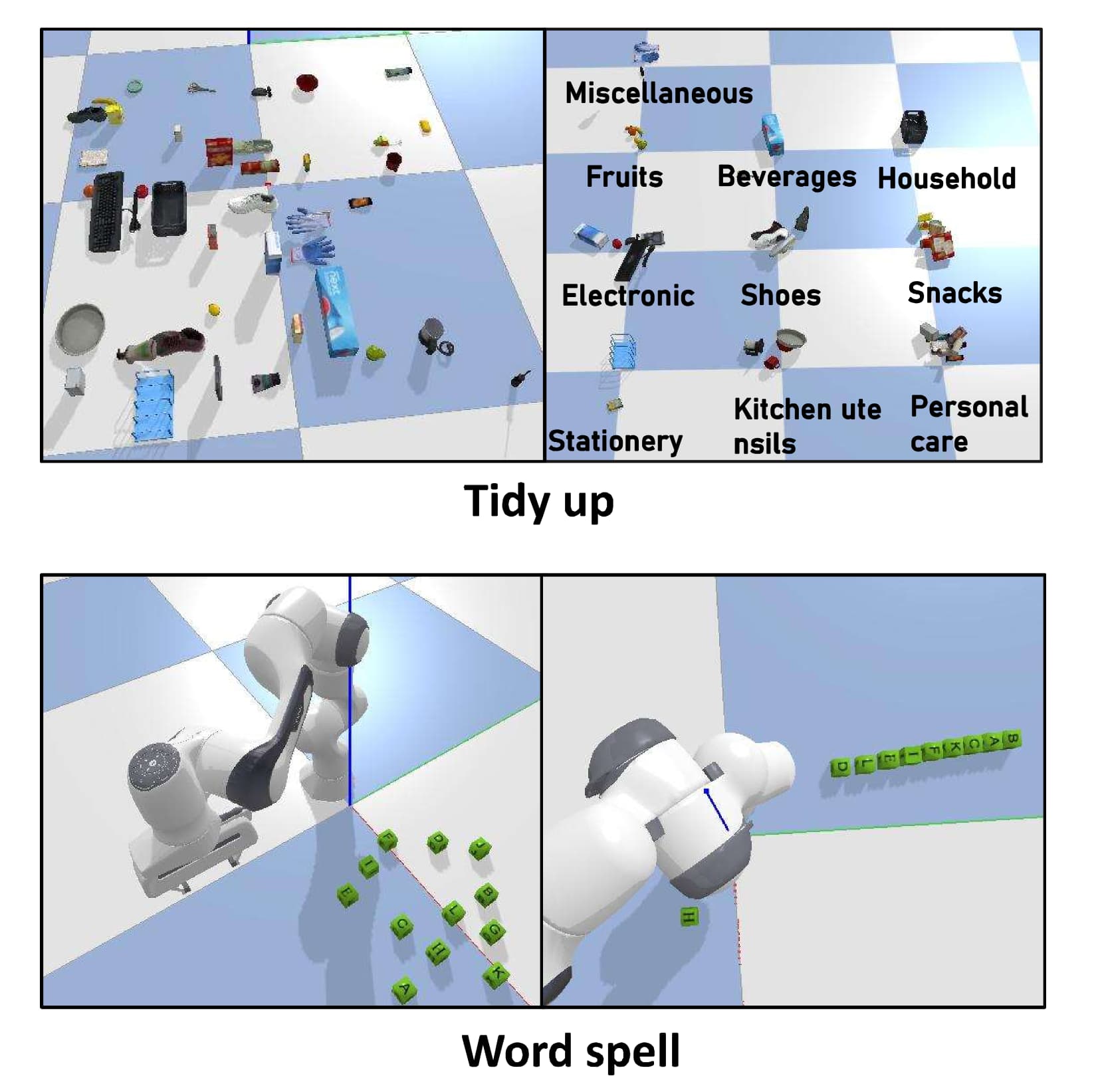
实验方案。 我们邀请十名参与者进行 AB 测试实验。其中七人有机器人开发经验,三人有图像处理经验。我们设定了 70 分钟的时间限制。参与者通过与 RobotGPT 相同的提示来了解开发需求。 他们被要求通过编程完成表五中列出的 10 项任务。 每个参与者都有自主权来决定他们尝试任务的顺序。
评估指标。 我们通过五个指标来评估性能:完成状态(CS), 对于人类参与,我们计算完成次数,至于RobotGPT是否完成;代码质量(CQ )是指生成的代码从0到1的分数,由Python的静态代码分析工具Pylint进行分析;时间使用(TU), 从读取任务要求到在模拟中实现任务所消耗的时间(以秒为单位);外部帮助(EH) 是指参与者是否在互联网上搜索信息;对于人体测试,CQ 、TU 和 EH 表示成功完成任务的个人数据的平均值。
结果与分析。 表V显示了AB测试的结果。与手工编码相比,RobotGPT 在代码质量和时间消耗方面都表现出优势,分别为 0.762 秒和 221.8 秒,而人类为 0.70 秒和 554.9 秒。只有五名参与者在 70 分钟内完成所有任务,因此即使对于具有强大编程背景的工程师来说,通过手动编码生成机器人演示数据也很耗时。
结论
总体而言,与直接使用 ChatGPT 作为任务计划器相比,利用 ChatGPT 作为专家来训练 RobotGPT 是一种更稳定的方法,但机器人和LLM的整合仍处于起步阶段。这次工作只是一个初步的探索,相信未来在这一领域的大部分研究是 探索如何在机器人领域正确使用ChatGPT的能力。