如果说我们在 2023 年学到了什么,那就是开源 AI 正在迅速普及。今年越来越多的高性能开源大型语言模型 (LLM) 正在涌现,用于研究和商业用途。虽然这些预先训练的开源 LLM 模型还没有达到取代 GPT4 等专有 AI 模型性能的阶段,但这些模型可以成为 GPT 3.5 等 LLM 的可行替代方案。下面,随着开源 AI 生态系统的不断发展,我们将看看 2024 年最值得关注的 6 个 LLM。

6. Llama 2:最佳开源 LLM 整体
优点
- 生成自然语言
- 针对聊天用例进行了微调
- 少镜头学习
- 多任务学习
- 与类似规模的 LLM 相比,使用的计算资源更少
- 翻译成多种语言
- 支持多种编程语言
- 产生更安全的输出
- 使用具有超过 100 万个人工注释的多样化数据集|* 培训可能在财务和计算上都成本高昂
今年推出的最重要的开源 LLM 之一是 Meta 的 Llama 2,由于其整体多功能性和性能,可以说是最适合商业用途的开源 LLM。
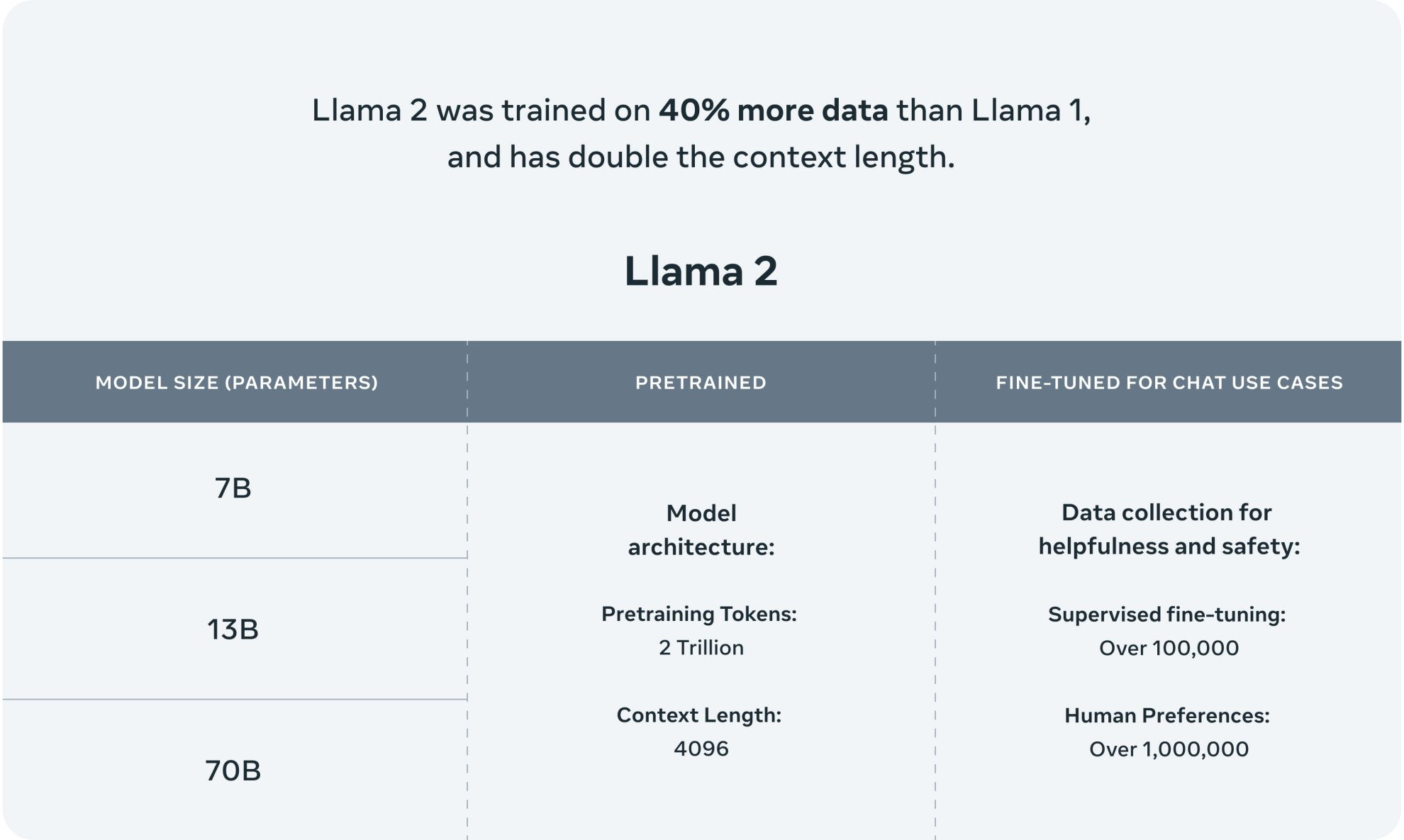
早在 7 月,Meta 和 Microsoft 就宣布发布 Llama 2,这是一个在 2 万亿个代币上训练的预训练生成式 AI 模型,支持 7 到 700 亿个参数。值得强调的是,Llama 2 的数据比 Llama 1 多 40%,并且支持两倍的上下文长度。在撰写本文时,Llama 2 仍然是市场上性能最高的开源语言模型之一,在推理、编码、熟练程度和知识测试等关键基准测试中表现出色。
目前,Hugging Face Open LLM 排行榜将 Llama 2 70B 列为市场上第二好的 LLM,平均得分为 67.35, ARC 得分为 67.32,HellaSwag 得分为 87.33,MMLU 得分为 69,83,TruthfulQA 得分为 44.92。Llama 2 在对抗 GPT4 等专有模型时也表现出了良好的性能。Anyscale 首席科学家兼 Google 前首席工程师 Waleed Kadous 发表了一篇博客文章,发现 Llama 2 的摘要准确率与 GPT-4 大致相同,同时运行成本也低 30 倍。值得注意的是,Meta 还有一个新版本的 Llama 2,名为 Llama 2 Long,旨在在响应长查询时表现良好。它是 Llama 2 的修改版本,带有 4000 亿个额外的代币,并支持 32,000 个上下文长度。
发布后,Meta 声称 Llama 2 Long 的 70B 变体在长上下文任务(例如回答问题、测试摘要和多文档聚合)上的性能超过了 GPT 3.5 16ks。
5. Falcon 180B:最强大的开放获取模型
优点
- 比 GPT 3.5 和 Llama 2 等流行工具更强大
- 生成文本
- 编写和调试代码
- 针对推理进行了优化
- 可用于研究和商业用途
- 对聊天和指令数据进行微调
- 使用各种数据(包括 RefinedWeb 数据集)进行训练|
2023 年推出的最大的开放 LLM(开放获取)之一是 Falcon 180B。阿拉伯联合酋长国技术创新研究所 (TII) 的语言模型使用从 RefinedWeb 数据集中获取的 3.5 万亿个代币进行训练,该数据集支持多达 1800 亿个参数。
它被设计为在完成自然语言任务方面表现出色,截至 2023 年 10 月,它是预训练语言模型的 Hugging Face Open LLM 排行榜上排名第一的 LLM,平均得分为 68.74、ARC 69.8、HellaSwag 88.95、MMLU 70.54 和 TruthfulQA 45.67。
TII声称Falcon 180B在推理、编码能力和知识测试方面“表现得非常好”,在某些方面优于Llama 2等竞争对手,并且与谷歌的PaLM 2“相当”,后者为流行的Bard聊天机器人提供动力。
想要在聊天机器人环境中试验Falcon 180B的研究人员可以使用名为Falcon 180B Chat的修改版本,这是主模型的修改版本,对聊天和指令数据进行了微调。

4. Code Llama:用于代码生成的最佳开放式 LLM
优点
- 能够生成自然语言和代码
- 模型的微调版本可用于聊天用例 (Mistral 7B Instruct)
- 更快的推理时间(通过分组查询注意)
- 降低推理成本(通过滑动窗口注意)
- 可在本地使用
- Apache 2.0 许可证没有限制
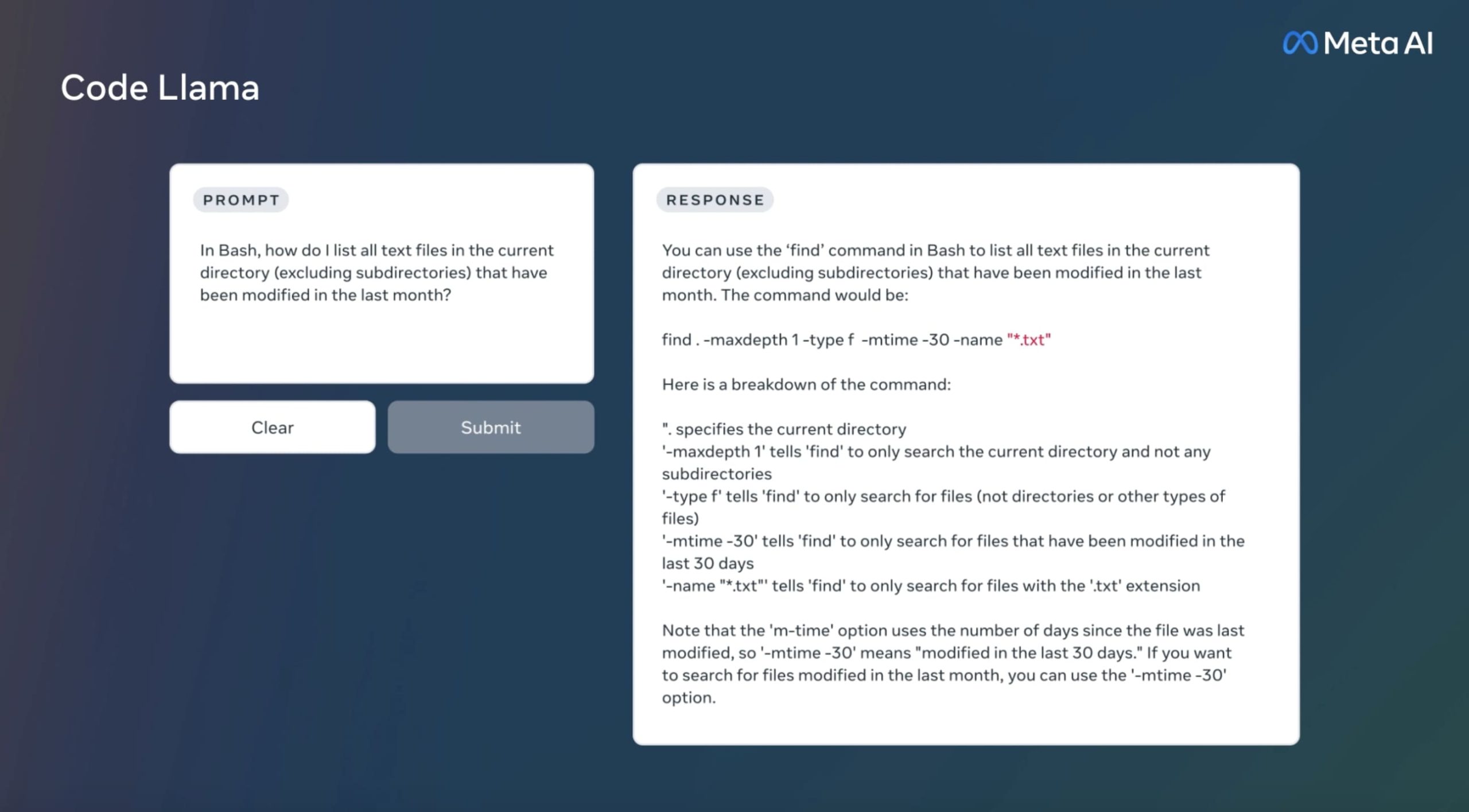
在代码创建方面,今年最激动人心的版本之一来自 Meta 的 Code Llama。它是一个 AI 模型,是通过在特定于代码的数据集上训练 Llama 2 创建的,包括 5000 亿个代码和代码相关数据的令牌。
Code Llama 支持 7B、13B 和 34B 参数,并经过微调以生成代码并解释代码在多种语言中的作用,包括 Python、C++、Java、PHP、Typescript (Javascript)、C#、Bash 等。
例如,用户可以要求聊天机器人编写一个输出斐波那契数列的函数,或者请求有关如何列出给定目录中所有文本文件的说明。
这使得它非常适合旨在简化工作流程的开发人员或希望更好地了解一段代码的作用及其tps://www.techopedia.com/definition/15823/fibonacci-sequence)的函数,或者请求有关如何列出给定目录中所有文本文件的说明。
这使得它非常适合旨在简化工作流程的开发人员或希望更好地了解一段代码的作用及其工作原理的新手编码人员。
Code Llama 有两种主要变体;Code Llama Python 和 Code Llama Instruct。Code Llama – Python 在额外的 100B 个 Python 代码令牌上进行训练,为用户提供更好的 Python 编程语言代码创建功能。
Code Llama Instruct 是 Code Llama 的微调版本,它经过 50 亿个人类指令令牌的训练,旨在更好地理解人类指令。
3. Mistral:最佳 7B 预训练模型
优点
- 生成自然语言和代码
- 模型的微调版本可用于聊天用例 (Mistral 7B Instruct)
- 快速推理时间(通过分组查询注意)
- 降低推理成本(通过滑动窗口注意)
- 可在本地使用
- Apache 2.0 许可证没有限制
2023 年 9 月,Mistral AI 宣布发布 Mistral 7B,这是一款具有 70 亿个参数的小型但高性能的开源 LLM,其开发比大型闭源模型更高效,非常适合支持实时应用程序。
Mistral 7B 使用分组查询注意力等技术进行更快的推理,并使用滑动窗口注意力 (SWA) 等技术以更低的成本处理更长的序列。
这些技术使 LLM 能够比资源密集型 LLM 更快、更低成本地处理和生成大型文本。
该组织的发布公告表明,Mistral 7B 在 arc-e 上得分为 80.0%,在 HellaSwag 上得分 81.3%,在 MMLU 上得分 60.1%,在 HumanEval 基准测试中得分 30.5%,在每个类别中都明显优于 LLama 2 7B。
Mistral AI 还表明,Mistral 在代码、数学和推理方面的表现优于 Llama 1 34B,同时在代码任务上接近 Code Llama 7 B 的表现。
总之,这些信息表明 Mistral AI 是自然语言和代码生成任务的可行选择。
2. 骆马:最佳尺寸输出质量 LLM
优点
- 生成详细的自然语言输出
- 轻
- 培训费用为 300 美元
- 对来自 ShareGPT 的超过 70K 对话进行了微调
- 商用
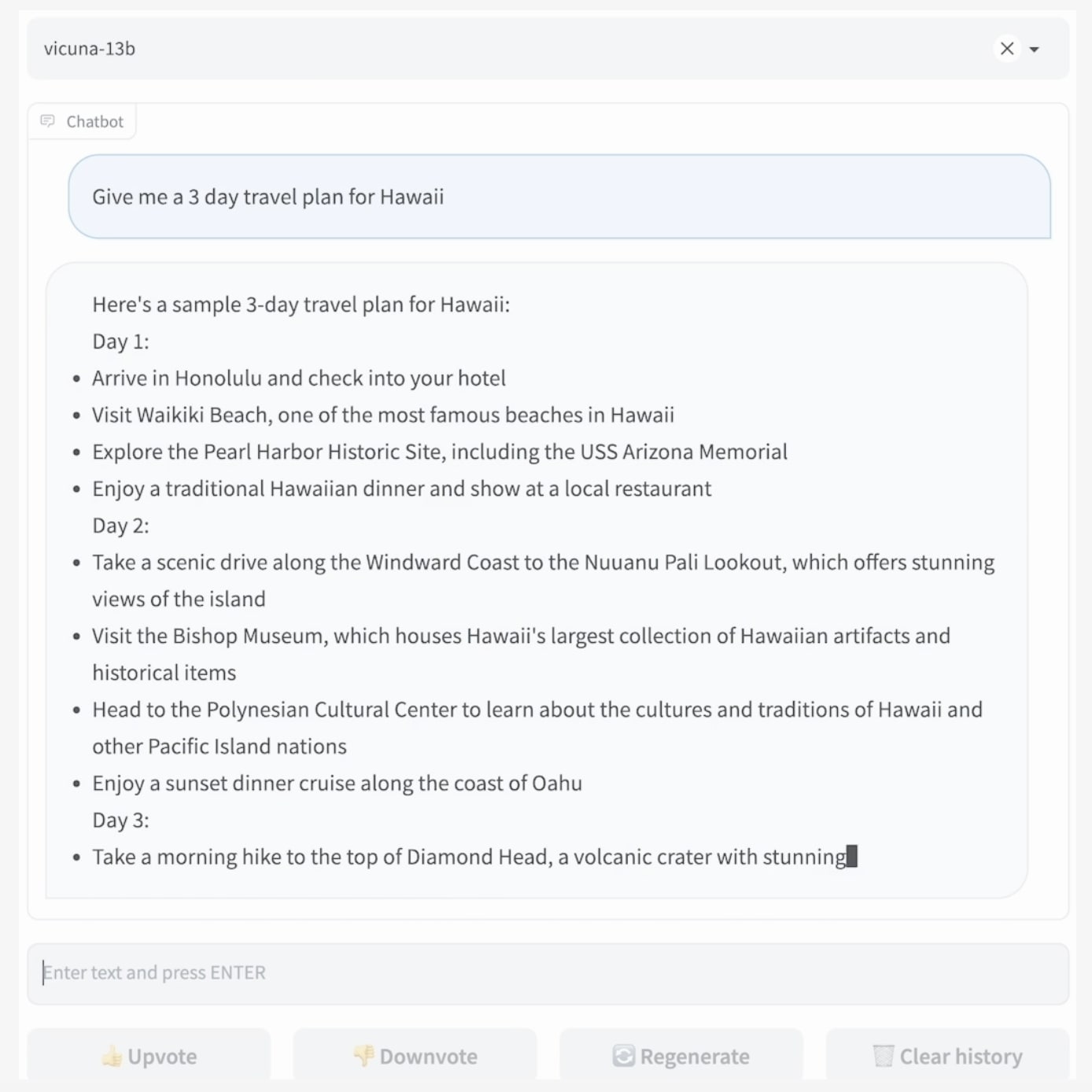
Vicuna 13B 是一个开源聊天机器人,由加州大学伯克利分校的学生和教职员工发布,早在 2023 年 3 月就在开放研究组织大型模型系统组织 (LMSYS Org) 下运行。
LMSYS Org 的研究人员采用了 Meta 的 Llama 模型,并利用用户在 ShareGPT.com 上分享的 70,000 个 ChatGPT 对话对其进行了微调。根据这些数据对骆驼进行训练,使 Vicuna 能够以与 ChatGPT 相媲美的复杂程度对用户查询生成详细而清晰的响应。
例如,LMSYS Org 进行的初步测试表明,Vicuna 达到了 ChatGPT 和 Bard 的 90% 的质量,同时在 90% 的场景中优于 Llama 和 Stanford Alpaca(尽管研究人员承认需要研究来全面评估该解决方案)。
LMSYS ORG 还报告说,Vicuna 13B 在 MT 板凳上获得了 6.39 分,竞技场 ELO 评分为 1,061,在 MMLU 上获得了 52.1 分。
同样,在对语言模型的指令跟随能力进行排名的 AlpacaEval 排行榜上,Vicuna 13B 的胜率为 82.11%,而 GPT-3.5 为 81.71%,Llama 2 Chat 70B 为 92.66%。
考虑到 Vicuna 13B 的训练费用约为 300 美元,这些结果令人印象深刻。
还有一个更大版本的 Vicuna 称为 Vicuna-33B,它在 MT-bench 上得分为 7.12,在 MMLU 上得分为 59.2。
1. 长颈鹿:最佳尺度-上下文长度模型

优点
- 理解和生成自然语言文本
- 大型上下文窗口支持更大的输入和更长的对话
- 16 模型应在长达 16K 上下文长度的任务中表现良好
- 提供 Vicuna 指令微调版本的模型
2023 年 9 月,Abacus.AI 发布了 70B 版本的长颈鹿,这是一个基于 Llama 2 的微调 AI 模型系列,将模型的上下文长度从 4,096 扩展到 32,000。Abacus.AI 为 Giraffe 提供了很长的上下文窗口,以帮助提高下游处理任务的性能。
扩展上下文长度使 LLM 能够从下游数据集中检索更多信息,同时减少错误。同时,它还有助于与用户保持更长的对话时间。
Abacus.AI 声称,长颈鹿在提取、编码和数学方面表现出所有开源模型的最佳性能。在 MT-Bench 评估基准下,70B 版本的长颈鹿获得了 7.01 分。
Abacus AI首席执行官Bindu Reddy表示:“我们在一组基准测试中对70B模型进行了评估,这些基准测试了LLM在长期上下文中的性能。
“与 13B 模型相比,70B 模型在文档 QA 任务的最长上下文窗口 (32k) 上有显着改进,在我们的 AltQA 数据集上,准确率为 61%,而 13B 的准确率为 18%。我们还发现,它在所有上下文长度上都优于同类 LongChat-32k 模型,在最长的上下文长度下性能不断提高(在 32k 上下文长度下记录 61% 和 35% 的准确率)。
还值得注意的是,Abacus AI 还报告说,长颈鹿 16k“应该在高达 16k 上下文长度的实际任务中表现良好”,并且可能高达 20-24k 上下文长度
原文链接:https://www.techopedia.com/6-best-open-source-llms-to-watch-out-for-in-2024